Yapay Zekâ Ajan Mimarisi
Önemli noktalar
- Yapay zekâ ajan mimarisi, prompt mühendisliği değil sistem tasarım disiplinidir — ele aldığı başarısızlıklar dilsel değil operasyoneldir.
- Bir ajan, standart bir LLM çağrısından durum tutması, çok adımlı planlaması, araç çağırması ve tek bir kullanıcı görevi içinde başarısızlıktan dönmesi yönüyle ayrılır.
- Üretime hazır ajan sistemleri açık bir orkestrasyon, deterministik araç sözleşmeleri, değerlendirme test kataloğu ve gözlemlenebilirlik gerektirir; hiçbiri model güncellemesiyle kendiliğinden gelmez.
- Ajan mimarisi; görev birden fazla aracı veya dallanan adımları kapsadığında doğru seçimdir. Tek seferlik üretim için düz bir LLM çağrısı hem ucuz hem güvenilirdir.
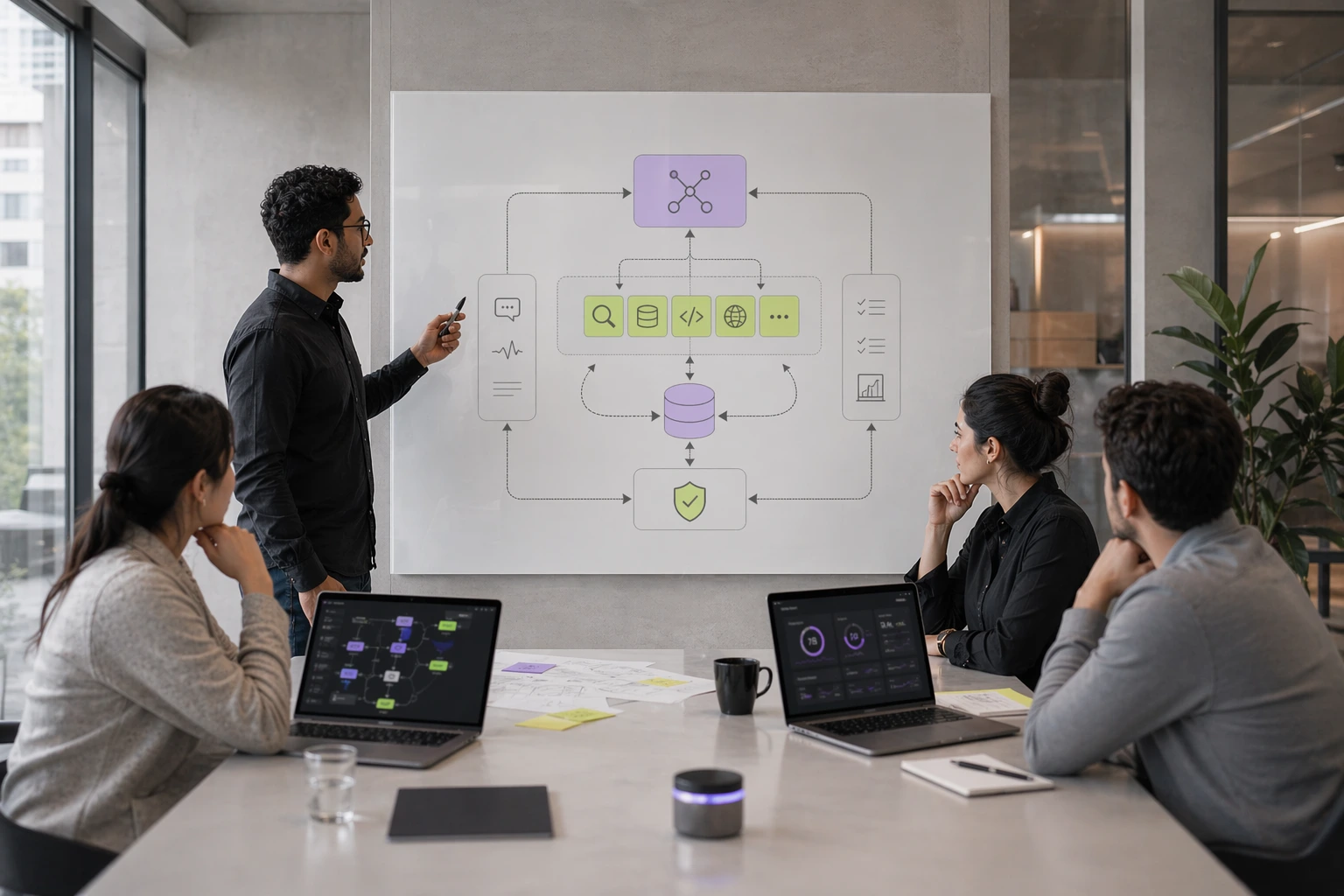
Bir yapay zekâ ajanı, gelişmiş bir sohbet botu değildir. Ajan, bir sistem mimarisidir: dil modelinin durumu algıladığı, görev üzerinde çıkarım yaptığı, araçları seçip çağırdığı, sonuçları değerlendirdiği ve devam edip etmeyeceğine karar verdiği bir döngüdür. LLM çağrısı ile ajan sistemi arasındaki fark mimari bir farktır — yetenek farkı değil — ve bu fark, ajan sistemlerinin nasıl başarısız olduğunu, nasıl değerlendirildiğini ve üretime hazır hâle gelmek için ne kadar mühendislik gerektirdiğini doğrudan belirler.
Bu ayrım operasyonel açıdan kritiktir. Standart bir LLM çağrısı durumsuz ve tek turludur: bir prompt gönderirsiniz, bir tamamlama alırsınız. Zekâ modeldedir; planlama ve sıralama sorumluluğu onu çağıran uygulama koduna aittir. Ajan mimarisi ise bu döngüyü içselleştirir. Bir sonraki adımda ne yapılacağına — hangi aracın çağrılacağına, sonucun görevi karşılayıp karşılamadığına, yeniden deneme mi yoksa eskalasyon mu gerektiğine — model karar verir. Model, yürütme sıralaması üzerinde özerkliğe sahiptir; bu hem gücünün hem de kendine özgü başarısızlık biçimlerinin kaynağıdır.
Bir ajanı standart LLM çağrısından ne ayırır
LLM çağrısı ile ajan arasındaki yapısal fark, model tarafından kontrol edilen bir karar döngüsünün varlığıdır. Standart bir ardışık düzende uygulama mantığı yürütmeyi kontrol eder: modeli çağır, tamamlamayı al, çıktıyı ayrıştır, ilerle. Model, deterministik bir dizideki tek bir adımdır.
Ajan mimarisinde ise döngüyü modelin kendisi yönetir. Bir görev tanımı ve kullanılabilir araç seti verildiğinde model sonraki eylemi belirler. Bir aracı çağırır, sonucu alır, bu sonucun görevi karşılayıp karşılamadığını değerlendirir ve ya bir yanıt döndürür ya da sonraki eylemi seçer. Bu döngü görev tamamlanana, bir çıkış koşulu sağlanana veya sabit bir tur limiti tetiklenene kadar devam eder.
Bu farkın pratik sonuçları:
Bu ayrım operasyonel açıdan kritiktir. Standart bir LLM çağrısı durumsuz ve tek turludur: bir prompt gönderirsiniz, bir tamamlama alırsınız. Zekâ modeldedir; planlama ve sıralama sorumluluğu onu çağıran uygulama koduna aittir. Ajan mimarisi ise bu döngüyü içselleştirir. Bir sonraki adımda ne yapılacağına — hangi aracın çağrılacağına, sonucun görevi karşılayıp karşılamadığına, yeniden deneme mi yoksa eskalasyon mu gerektiğine — model karar verir. Model, yürütme sıralaması üzerinde özerkliğe sahiptir; bu hem gücünün hem de kendine özgü başarısızlık biçimlerinin kaynağıdır.
Logic Grid Studio
Ajan mimarisinin temel bileşenleri
Üretime hazır bir ajan sistemi, her biri kendi mühendislik kaygılarına sahip dört işlevsel katmandan oluşur:
Akıl yürütme modeli. Durumu değerlendiren, planlar üreten ve sonraki eylemleri seçen dil modeli. Model seçimi; akıl yürütme kapasitesi, gecikme, maliyet ve çıktı öngörülebilirliği arasındaki dengeleri içerir. Daha yetenekli modeller araç seçimi ve argüman üretimindeki halüsinasyonu azaltır ancak çok turlu iş akışlarında adım başına maliyeti artırır. Sistem kalitesindeki tek değişken model değildir — araç tasarımı ve değerlendirme altyapısı, farklı görev türleri arasında daha tutarlı biçimde belirleyicidir.
Araç katmanı. Ajanın çağırabileceği fonksiyonlar, API'ler, veritabanları ve harici sistemlerin tümü. Ajan başarısızlıklarının çoğu araç tasarımından kaynaklanır: belirsiz araç açıklamaları yanlış araç seçimine yol açar; yetersiz hata yönetimi modelin çıkarım yapamayacağı tipsiz hata durumları üretir; yapılandırılmış çıktılar yerine düz metin döndüren araçlar güvenilmez zincirleme davranış üretir. İyi araç tasarımı bir sistem tasarımı disiplinidir, prompt mühendisliği sorunu değildir.
Durum ve bellek katmanı. Birden fazla adımda çalışan ajanlar, önceki eylemleri, sonuçları ve bağlamı takip etmek için bir mekanizmaya ihtiyaç duyar. Bellek uygulamaları; bağlam penceresi yönetiminden (hızlı, bağlam uzunluğuyla sınırlı) harici vektör depolarına (ölçeklenebilir, erişim gecikmeli) ve yapılandırılmış oturum durumuna (güvenilir, şema tasarımı gerektirir) uzanır. Seçim; oturum uzunluğuna, bağlam penceresi kısıtlarına ve gecikme gereksinimlerine bağlıdır.
Yürütme denetleyicisi. Tur limitlerini, hata eşiklerini, yeniden deneme mantığını ve ajanın alabileceği eylemlerin kesin sınırlarını yöneten orkestrasyon katmanı. Bu katman temel güvenilirlik denetim mekanizmasıdır. Model döngüye girdiğinde, bir araç hata döndürdüğünde, alt akış bir hizmet kullanılamaz olduğunda ve ayrıcalıklı bir eylem talep edildiğinde sistemin ne yapacağını belirler.

Orkestrasyon kalıpları ve araç kullanımı
Üretim ajan sistemlerinde birkaç orkestrasyon kalıbı kararlı hâle gelmiştir. Doğru seçim; görev yapısına, gecikme toleransına ve yürütme ortası hatalarının planlama hatalarına kıyasla göreli maliyetine bağlıdır.
ReAct (Akıl yürütme + Eylem). Model; planlama adımları — sonraki adımı planlama, önceki sonucu değerlendirme — ile eylem adımları — bir aracı çağırma, sonucu bekleme — arasında dönüşümlü olarak ilerler. Gözlemlenebilir, hata ayıklamaya uygun ve ajan uygulamalarının büyük çoğunluğu için doğru başlangıç noktasıdır. Akıl yürütme adımlarının izi, ajan hata analizinde en yararlı tanılama araçlarından biridir.
Planla-ve-yürüt. Model, herhangi bir araç çağrısına başlamadan önce eksiksiz bir yürütme planı üretir. Plan daha sonra, potansiyel olarak daha düşük yetenek gereksinimine sahip ayrı bir yürütme modeliyle icra edilir. Görev ortasında bağlam sapmasını azaltır ve öngörülebilirliği artırır, ancak hata riskini ön planlama adımına kaydırır. İyi tanımlanmış yapıya ve düşük belirsizliğe sahip görevler için uygundur.
Çoklu ajan orkestrasyonu. Uzman alt ajanlar tanımlanmış görev kapsamlarını yönetir ve sonuçları koordinatör ajan'a döndürür. Sistem karmaşıklığını ve hata ayıklama yükünü belirgin biçimde artırır. Yalnızca görev ayrıştırmasının gerçekten ayrı uzmanlıkların net izolasyonunu ürettiği durumlarda uygundur — yetenek eklemek için varsayılan mimari olarak değil.
Tüm orkestrasyon kalıplarında üretim başarısını tutarlı biçimde belirleyen araç tasarımı ilkeleri:
Güvenilirlik, değerlendirme ve başarısızlık biçimleri
Ajan sistemleri, basit LLM ardışık düzenlerinde var olmayan kategorilerde başarısız olur. Her başarısızlık kategorisi farklı bir azaltma stratejisi gerektirir:
Döngü. Ajan, hiçbir çıkış koşulu karşılanmadığı için yinelemeye devam eder. Model bir plan üretir, bir araç çağrısı yapar, sonucu yetersiz olarak değerlendirir ve süresiz yeni bir plan üretir. Sessiz bir takılma yerine yapılandırılmış bir hata yüzeyleyen kesin tur limitleri üretimde tartışmasızdır.
Halüsinatif araç kullanımı. Model, geçerli seçeneklerle eşleşmeyen araç çağrı argümanları üretir — var olmayan parametrelere atıfta bulunur, sahte kimlikler üretir, hatalı biçimlendirilmiş API yükleri oluşturur. Tüm araç çıktıları üzerlerinde işlem yapılmadan önce doğrulanmalı, tüm araç çağrı argümanları gönderilmeden önce şema doğrulamasından geçirilmelidir.
Bileşik hatalar. 2. adımdaki bir hata veya yetersiz sonuç, nihai çıktıda görünür hâle gelmeden önce 3–6. adımlara yayılır. Ajanın planı, hatalı ara sonuçlara dayansa bile kendi içinde tutarlı olabilir. Bu hata sınıfını tespit etmek için adım düzeyinde değerlendirme — yalnızca son yanıtın değil, her eylemin doğruluğunun sorgulanması — gereklidir.
Güvensiz eylem yürütme. Yazma, gönderme veya silme işlemlerine erişimi olan ajanlar, hem doğru hem de yanlış yürütme yollarıyla geri dönüşü olmayan zarara neden olabilir. Ayrıcalıklı araçlar döngüde insan onayı kontrol noktası gerektirir; uygulama kalıbı — yan etkili araç gönderimi öncesinde açık kullanıcı onayı talep etme — standart pratiktir ve isteğe bağlı değildir.
Ajan sistemleri için değerlendirme, yalnızca tek turlu kaliteyi değil çok adımlı görev yollarını sınayan test takımları gerektirir. Yörünge değerlendirmesi — her adım doğru atıldı mı, model doğru aracı mı seçti, argümanlar geçerli miydi — yalnızca nihai çıktı değerlendirmesinden daha yüksek sinyal sağlar. Nihai çıktı kalitesi, birbirini iptal eden ara hatalarla bile kabul edilebilir olabilir; yörünge değerlendirmesi gerçek güvenilirlik tablosunu ortaya koyar.
Ajan mimarisi ne zaman doğru tercihtir
Ajan mimarisi herhangi bir yapay zekâ sistemine önemli mühendislik karmaşıklığı ekler. Belirli koşullarda doğru tercihtir ve yaygın olarak önerildiği birçok durumda yanlış tercihtir.
Ajan mimarisi şu durumlarda uygundur:
Ajan mimarisi şu durumlarda yanlış tercihtir:
Logic Grid Studio'nun Yapay Zekâ Sistemleri hizmeti, daha geniş bir yapay zekâ entegrasyon projesi kapsamında ajan sistemlerinin mimarisini, uygulamasını ve değerlendirmesini kapsar. Hizmetler sayfası bunun LLM entegrasyonu, platform mühendisliği ve yazılım teslimatıyla pratikte nasıl ilişkilendiğini açıklar.
Sıkça sorulan sorular
Tek bir LLM promptu yerine ne zaman ajan kullanmalıyım?
Görev; çok adımlı, koşullu dallanmaya sahip, dış araç ya da sistem çağrılarına ihtiyaç duyan veya ara başarısızlıklardan dönmesi gereken bir akışsa ajan kullanın. Özetleme, sınıflandırma, biçim dönüştürme gibi tek geçişli üretimler için doğrudan LLM çağrısı daha ucuz, hızlı ve değerlendirmesi daha kolaydır.
Üretimde LLM ajanlarının en yaygın başarısızlık biçimleri nelerdir?
Var olmayan bir aracı veya hatalı argümanlarla çağırma, bütçeyi tüketen ama ilerleyemeyen muhakeme döngüleri, durum modelin penceresini aştığında sessizce yapılan bağlam kırpması ve modelin spec dışına biraz çıktığında çöken çıktı çözümleyici.
Bir ajan sistemini sahaya almadan önce nasıl değerlendiririm?
Mutlu yolları, başarısızlık kurtarmalarını ve uç durumları kapsayan uçtan uca görevlerden oluşan sabit bir değerlendirme kataloğu kurun. Görev başarısı, araç çağrısı doğruluğu ve çözüm başına maliyet üzerinden puanlayın. Çok adımlı sistemlerde sadece nihai cevaba bakan bir puanlama yetersiz kalır.

İlgili hizmetler
 Bir sonraki sisteminizi birlikte planlayalım.
Bir sonraki sisteminizi birlikte planlayalım.


0 Yorumlar
Görüşünüzü paylaşın
Bu konudaki soruları, düzeltmeleri veya yorumları okuyoruz. E-posta adresiniz yayımlanmayacaktır.